人工智能与芯片技术的协同发展 首都海智创新链接系列活动干货分享之人工智能基础软件开发篇
在数字化转型浪潮席卷全球的背景下,人工智能(AI)与芯片技术的深度融合已成为驱动新一轮科技革命与产业变革的核心引擎。近日举办的“首都海智创新链接”系列活动,聚焦于这一前沿交叉领域,为业界与学术界搭建了深度交流的平台。本文将围绕活动中的精华内容,特别是关于“人工智能基础软件开发”的关键议题,进行梳理与解读,以飨读者。
一、协同发展的必然性:AI算法与芯片硬件的双向奔赴
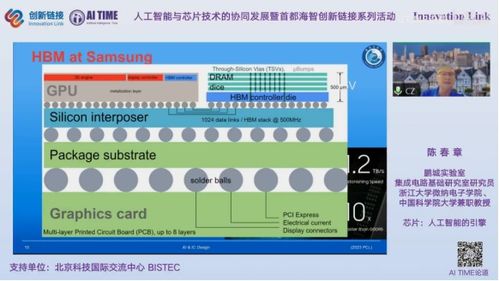
人工智能的飞速发展,尤其是深度学习模型的复杂化与规模化,对底层计算硬件提出了前所未有的要求。传统的通用处理器(CPU)在处理海量矩阵运算、并行计算任务时逐渐显得力不从心。因此,专为AI计算设计的芯片(如GPU、TPU、NPU及各类AI加速芯片)应运而生。
反之,新型芯片架构的出现,也深刻改变了人工智能软件的开发范式。软件开发者不能再仅仅关注算法逻辑,而必须深入理解硬件特性,进行针对性的优化,以充分释放硬件的算力潜能。这种“软硬协同”设计,从模型设计、框架适配到编译优化,贯穿了整个AI基础软件栈。
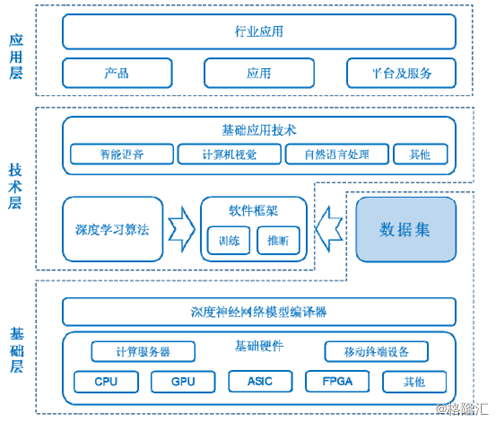
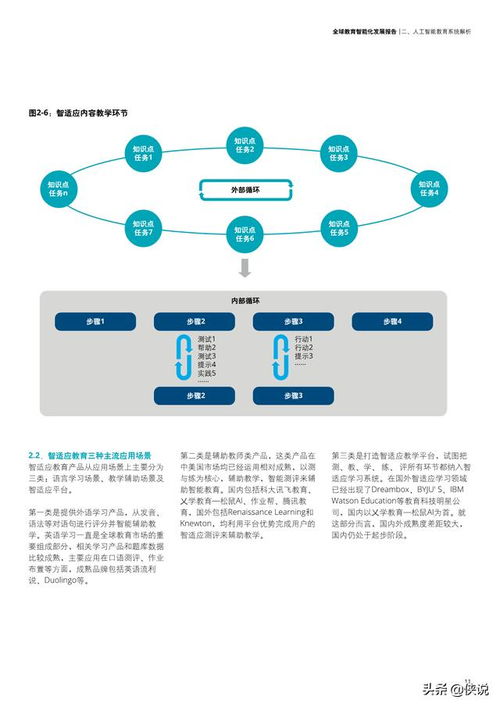
二、人工智能基础软件的核心层与挑战
活动中,专家们指出,AI基础软件是连接上层AI应用与底层AI芯片的“桥梁”和“操作系统”,其核心主要包括:
- 计算框架与编译器: 如TensorFlow、PyTorch等主流深度学习框架,及其配套的编译器(如XLA、TVM)。它们的核心任务是将高级的模型描述,高效地映射到底层异构硬件(包括不同厂商的CPU、GPU、AI加速卡)上执行。挑战在于如何实现“一次开发,多处高效部署”,解决硬件碎片化带来的兼容性与性能优化难题。
- 算子库与高性能计算库: 这是性能的关键。针对特定芯片架构,高度优化的基础算子(如卷积、矩阵乘法)库(如cuDNN for NVIDIA, oneDNN for Intel)能带来数倍甚至数十倍的性能提升。开发这类库需要深厚的硬件架构知识、并行编程及算法优化功底。
- 驱动与运行时系统: 负责管理硬件资源、任务调度、内存分配等,确保AI计算任务能够高效、稳定地在芯片上运行。随着算力集群规模扩大,跨节点的任务调度与通信优化成为重中之重。
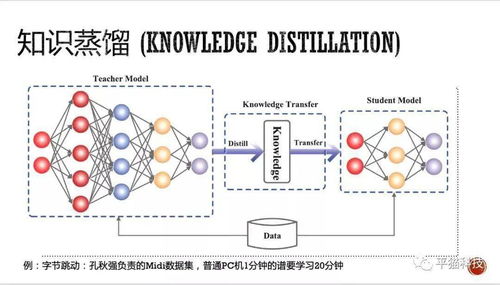
- 模型压缩与部署工具链: 为了将庞大的AI模型部署到资源受限的边缘端或终端芯片上,需要一套完整的工具进行模型剪枝、量化、蒸馏等优化,以及最终的轻量化部署。这要求软件工具能紧密配合芯片的特定计算单元(如整数单元、张量核心)。
三、活动干货:协同优化的实践路径
系列活动的讨论形成了多项共识与建议:
- “框架-芯片”协同设计: 鼓励AI芯片厂商与主流开源框架团队早期合作,将芯片特性(如特殊指令集、内存层次)作为一等公民融入框架设计中,而非事后适配。
- 标准化与开放生态: 推动中间表示层(如MLIR)、算子接口、编程模型(如SYCL)的标准化,降低开发者的移植成本,繁荣应用生态。这是打破当前一定程度“软硬绑定”局面的关键。
- 全栈人才培育: 亟需培养既懂AI算法又懂计算机体系结构、编译原理的复合型人才。他们能够进行跨层优化,在算法创新与硬件极限之间找到最佳平衡点。
- 重视基础软件投入: 认识到基础软件的长期性与战略性。它不仅是性能工具,更是产业生态的控制点。需要国家、企业加大持续投入,构建自主可控的AI软件根技术。
四、展望:构建自主创新的AI算力底座
“首都海智创新链接”系列活动清晰地揭示,人工智能的未来竞争,不仅是算法模型的竞争,更是“算法+芯片+基础软件”所构成的整体算力体系的竞争。人工智能基础软件开发,正处于这一体系的核心枢纽位置。
对于我国而言,在推进高端AI芯片研发的必须同步发力,构建与之深度协同、自主演进的基础软件栈。这是一项艰巨但至关重要的系统工程,需要产学研用各界的紧密合作与长期坚守。唯有软硬兼修、协同创新,才能夯实智能时代的算力基石,赢得未来发展的主动权。
如若转载,请注明出处:http://www.ympabiw.com/product/3.html
更新时间:2026-05-14 20:57:13